devCellPy: Finding Strong Signals in Noisy RNAseq Data
Adrienne Mueller, PhD
December 9, 2022
Single cell RNA sequencing is a groundbreaking new technique that has provided novel insights into the development and fates of cell types across tissues and organisms. However, single cell RNA sequencing data is dauntingly large and complex. For each cell, the RNA profile can change over time, or share similarities with numerous different cellular profiles.
Researchers are often obliged to resort to manual annotation of cell types – which is problematic because it can lead to different labels being applied by different research groups and result in poor reproducibility of future experiments. Even when tools have been developed to automatically classify cells, they have struggled to handle RNA sequencing data that changes over time or from cells that exhibit multiple identities; a situation that often arises during development.
A group of investigators led by Francisco Galdos, PhD, and Sidra Xu in the lab of Sean M. Wu, MD, PhD, turned to bioinformatics to develop a tool capable of handling the complexity of single cell RNA sequencing data. They created devCellPy – a machine learning-enabled pipeline for automated labeling of complex single-cells RNA data – and their results were recently reported in Nature Communications.
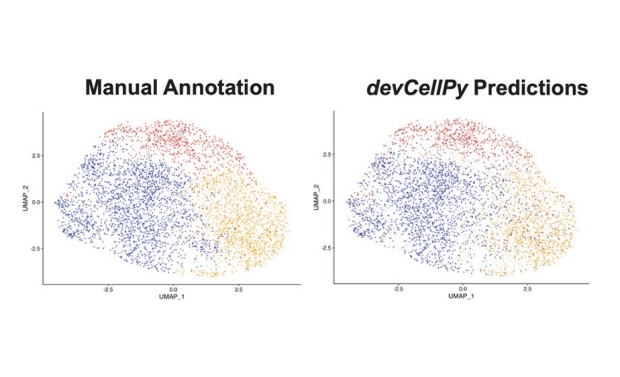
DevCellPy is an open source and fully automated pipeline cable of identifying different cell identities with extremely high accuracy.
What makes devCellPy stand out from its predecessors? It’s versatile, generalizable, and highly accurate. devCellPy uses a supervised machine learning method to create decision trees to identify features that allow it to make highly accurate predictions about a cell’s identity. In their study, devCellPy was able to generate a mouse cardiac development atlas from published datasets of over one hundred thousand cells between embryonic days 6 and 16. Their new approach had a prediction accuracy of more than 90% across multiple layers of annotation.
Also, devCellPy will work with any tissue from any species. The investigators also tested their pipeline on human heart cell data and discovered that many cells – far more than expected – actually have left ventricular identities. This result was also validated using a separate approach. In addition to its high performance, devCellPy is open source and freely available on github and on pypi.org.
In summary, the Sean Wu lab has developed a powerful new tool to quickly and accurately decipher the enormous datasets being generated by single cell RNA sequencing studies. devCellPy will allow us to make new and more accurate insights into the ways our cells behave across tissues, timelines, and species.
Additional Stanford Cardiovascular Institute-affiliated authors who participated in this study include William R. Goodyer, Lauren Duan, Yuhsin V. Huang, Soah Lee, Han Zhu, Carissa Lee, Nicholas Wei, and Daniel Lee.

Francisco Galdos, PhD

Sidra Xu

Sean M. Wu, MD, PhD